
The next 50 years of cyber security.
Making our risks as quantifiable and predictable as the weather.
There’s a massive need for the world to get better at cyber security. Let’s explore specific hurdles that are holding us back… not from the standpoint of the individual or team, but as an industry as a whole.
While this concern feels like a very wide problem, we will be discussing specific problem areas within it.
This isn’t a motivational essay, the following includes industry sized action items.
Observable gaps prevent our industry from operating in a rational, scientific and organized way. I think that the information security industry is currently stalling due to:
- A lack of classification methods around the root causes of breaches.
- A lack of transparency into the root causes of data breaches.
- A lack of probabilistic methods for those who practice cyber security.
Risk measurement limitations are holding us back.
Only a collective drive from this industry and its communities toward quantifiable methods and goals will allow us to build a future we’re proud of.
First I’ll offer some commentary on several observations of mine, and then I will follow up with specific areas of opportunity.
Can we “solve” cyber security with a focus on efficiency?
We can look into various industrial histories to understand their rapid acceleration, and our industry’s gaps become clear. I will describe this pattern briefly, and discuss specific goals for the information security industry over the long term.
Many industries have revolutionized themselves through measurement.
Similar to us, these industries include periods of time where their problems were pretty well understood… without any impact at scale.
That is, until a measurement mindset comes along that demands that an industry become more efficient.
Just a few examples:
- Modern epidemiology brought countless innovations. Doctor visits increased lifespans instead of signaling an imminent death.
- Henry Ford’s obsession with production line efficiency ushered us into a modern age of manufacturing.
- Meteorology’s big gains began around 1950 when quantitative forecasting met increasingly robust and organized measurement capabilities.
Going forward, I will make comparisons between security and meteorology, which we share many similarities with.
From 1900 to 1950, meteorology is marked with discovery, theory, and experimentation. 1950 and onward is easily described as a global effort to build data rich, accessible, and quantitative prediction infrastructure.
Much like pre-1950 meteorology, the history of computer security has always been about of innovation. We’ve invented and built most of the tooling, infrastructure, skills, and language so that we can perform jobs that mitigate risk. We have a proud industry that proves our concepts, but we’re failing.
What does it take to start a similar “50 year” effort?
It will require massive collaboration, activism, regulation, and agreeable forecasting methods to take advantage of it.
How would this change a security strategy?
Probabilistic security infrastructure should make our efforts as an industry, disparate security teams, and community, far more efficient and rational.
I view our collective progress so far as a constellation of disparate security innovations, mostly independent of one another. Singular products, innovations, systems, tools, or norms that have helped us mold our own unique security programs.
Until we can unify and direct these efforts into a rational approach to the security problem, we resemble an unfocused mass of conflicting goals.
We’re missing something. It is a beast with many names.
It is roughly described as “quantitative decision making” and it’s a foundation for nearly every industry that has found a way to mature and scale.
Once an industry has the necessary war chest of tooling and innovation, it begins intense measurement of itself to compete or produce at higher levels.
Here’s some buzzwords you may peruse to explore flavors of these mindsets:
Epidemiology. Process Optimization. Six Sigma. Lean Manufacturing. Kaizen. TPS. DFM. Quality Management. Validated Learning. Taylorism. Operations Research.
A strategy of investments in measurement, iterative improvement, and quantitative decision making is present throughout.
What will we name ours? And, where has it been for so long?
Why aren’t we measuring ourselves like other industries?
The root cause of this issue is quite ironic. We do not invest in prolific tracking of data breach root causes.
The tough part is: Even with plentiful root cause data, a modern security team rarely knows what to do with this information. They wouldn’t know how to contribute back to it, or measure their progress towards reducing the likelihood of outcomes related to these root causes.
Security teams that do not quantitatively measure a reduction of risk over time are simply hoping that their actions will change a future outcome. Hope is no strategy, and these actions are easily comparable to a rain dance, a cargo cult, or that cliche quote about insanity and expecting results.
I’ve previously believed that information security risk is too nuanced to be seriously measured in true quantitative ways. I’ve felt that measurement methods would not be as efficient as the intuition and leadership of talented individuals who develop strategy for a security team. I’ve since been convinced otherwise while coming to understand the role scenario based forecasts and rigorous estimation across a variety of industries.
Security teams operate far too differently from one another.
In my working with many security teams over several years, nearly all exhibit substantial bias and irrational intuitions towards risk by few influential people. The teams I have run have suffered the same, by my own doing. This is especially evidenced by how drastically one company, or team, will approach risk from the next, even within the same competitive sector.
Further, sea changes can occur with changes in leadership. One specific company I’ve discussed this with has gone through four leadership changes in about as many years, each with a totally different approach towards risk, with employees being asked to engage a new school of thought each time. I see this at different scales on a regular basis.
Did one leader have it “right”? More likely, they were arbitrarily chosen.
I’ve heard them all. Here are some examples:
- “Compliant”. Religiously following prescribed rules / regulation.
- “Customer first”. Prioritizing / satisfying customer checklists.
- “Standards based”. Embraces an industry maturity model or standard.
- “Threat driven”. Practicing threat intel and prioritizing adversary goals.
- “Reference organizations”. Be exceptional upon comparison to others.
- “Detection first”. First class detection allows more lenient security.
- “One of everything”. Never be accused of negligence.
- “Metric Driven”. Picking metrics as proxies for “risk” and reducing them.
- “Chaos” or “Iterative”. Constantly breaking, observing, and fixing.
Intuition of an “expert” is usually how these, or some combination of, are arrived at. Not through any sort of structured decision making approach.
Expert intuition is fallible under many conditions, and this is a big issue in an industry concerned with risk.
I’m no exception, my intuition is equally unreliable. My intuition has always desired incident response capability and powerful logging at the forefront of a team’s strategy. I could argue why this approach is superior… but so could the champion of every other approach. Why would I be different? Or you?
Had there been scientific methods to build teams focused on risk, I wouldn’t observe such drastic strategic differences on a regular basis, and we wouldn’t argue so much over superior methods, products, or strategies. We’d argue about how we chose a strategy, or more specifically, the choices we made to reduce risk, and why they were better than others, through a scientific method as opposed to spouting influential words strung together.
A scientific approach to risk can be accelerated with an understanding of the required, shared infrastructure we need. There is good reason for hope. There is prior art to leverage in measurement of risk from other industries, and security engineers have ample opportunity to make this tooling efficient for information security and tech companies.
There are 3 things we need to move ourselves forward.
Our guidance lives in other fields. I pay special attention to the aerospace, nuclear, and especially the industry of weather prediction. I spend most of my open time these days bothering professionals in these spaces. I want to be as full of knowledge on this subject as I am with incident response.
These industry lessons are supported by further critical findings in economic and psychological fields, in how we make rational decisions based on complex information. This research is robust, credible, and Nobel prize winning. I expect we will rely on these lessons to make up for (hopefully temporary) data shortcomings in security that we need to catch up on.
Now I will describe what I believe to be a triad of specific weaknesses in how the security industry deals in risk. These are heavy issues that slow our industry from turning a corner towards an era of efficiency.
They are inspired by how we differ from other industries that are far along in managing risk.
1. Classification language for root causes of a breach.
We are currently too satisfied with the typical availability and quality of breach data. It is unstructured, not timely, not accessible, and rare.
You might disagree and point me to the Verizon Data Breach Report. You may point me to Troy Hunt’s blog. You may point me to the Privacy Rights Clearinghouse, or the Blockchain Graveyard. Or Krebs. Or IC3 or your local infraguard.
I would argue that we should not be satisfied with breach data being tied up in journalism, blogs, PDFs, and local meetings. This is does not create the foundation for forecasting infrastructure with is critical to a rapidly paced approach to risk.
Can you even imagine how bad our lives would be if we limited our weather forecasters to blog posts, PDFs, and email bulletins?
While the status quo is invaluable to our understanding of trending risks, they fall very short in building the underlying infrastructure that can be used to predict risk, and increase our reliance on forecasting it. The potential of shared root cause infrastructure is massive.
There’s opportunity here. We are really good at classifying different forms of vulnerabilities and attack methods. But as far as data breaches go: the industry, press, and regulators are satisfied with “they got hacked” as a root cause. This is an unacceptable standard, considering that we should be ambitious towards mitigating risk.
I took a stab at root cause classification: The Blockchain Graveyard.
I have personally tried to take a crack at this classification problem with a focus on cryptocurrency (“c12y”). C12y companies see frequent breaches.
Surprisingly, c12y victims discuss root causes publicly. Because of this transparency, it has been an opportunity to at least estimate the root causes associated with each. This provides probabilistic leverage in understanding why c12y startups get hacked so frequently, and why, and the mitigations that have the most value in reducing the probability of a breach.
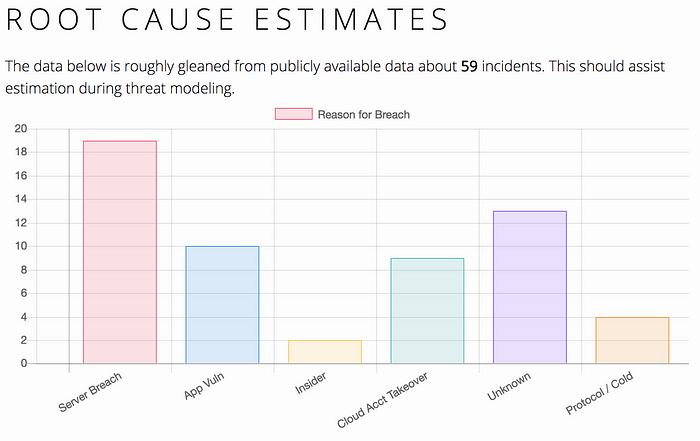
A security effort at a c12y business can use these estimations to inform and prioritize realistic, probable scenarios over naive checklists, FUD, or intuitive guesses.
The c12y product companies I have worked with exhibit far more rational, data driven approaches to security as a result, before I even show up. They have the advantage of root cause data being obvious and accessible to them.
I must admit though — the Blockchain Graveyard is an independent and mostly hobbyist effort. It does not organize trends based on a standard root cause language, and likely has author bias in how I estimate these root causes.
Other industries demand proper incident classification.
With my attempt at this with the Blockchain Graveyard, it confirmed my beliefs about the difficulties of classifying breaches, but didn’t convince me it wasn’t possible. Part of this reason is that meteorologists are fantastic at classification. In some ways, their problem is easier than ours, in some ways, harder. Most weather is very tightly defined to be compatible with probabilistic forecasting infrastructure.
When a massive disaster hits, we aren’t satisfied with “The WEATHER killed a thousand people”. We’d demand strict language to describe what happened.
Meteorologists are more satisfied with “A Category 4 hurricane killed a thousand people” or “An EF5 Tornado was not predicted and caused $10m in damages”.
When a clearly specified event occurs, there’s a rush in meteorology to understand how the event could have been better predicted and mitigated, earlier and more specifically, and which models failed, and which succeeded.
Meteorologists rely on significant observable data related to weather events, and forecast likelihoods associated with them in the future. Tweaking takes place and forecast infrastructure becomes smarter going forward, and their prior beliefs about a future event change continuously.
Compare that to the absurdity of this security industry. We are very used to “Company hacked! Thousands of customers breached!”. We are often left without a root cause. Or, the lessons are lost in a news archive after a couple weeks.
Victims don’t have any standard language to describe their root cause anyway. If a root cause does happen to be available, it’s tucked away in journalism instead of a statistical resource. We gain no probabilistic edge against our risks and have less leverage to forecast with.
There’s plenty of optimism around classification.
Our industry is pretty good at classifying nuanced, narrow aspects of security.
We have lots of threat modeling and vulnerability classification prior art to leverage. We can describe the major contributors to a breach in classifiable, countable ways. Right now we have pockets of this with the Mitre ATTACK framework and OWASP ASVS, and CVE, but there are enormous classification gaps.
Take for instance: cellular account compromise, an insider abusing access due to a love interest, or the recent nuance of lateral movement being employed by ransomware. These trends are not satisfied with broad “auth ”, “insider”, or “malware” classifications. What standards do we use that allow us to rapidly discover and count trends?
We need flexible classification methods to describe root causes, instead of being satisfied by apology blog posts and victim quantity estimations.
For instance, we can observe through manual analysis of data breach notifications that small business tax preparation shops are heavily currently targeted right now via with spearphishing, social engineering, and credential re-use against RDP implementations for W2 theft that results in tax fraud.
This puts small accounting firms at a far higher risk of being targeted beyond the standard risk of any general employer issuing W2’s to their employees.
In a better future, this could be an easily queryable observation done in real time. Then when a security team sounds an alarm: it is less chicken little and more cooperative instead.
With accessible methods to classify root causes, we can then step into powerful and probabilistic methods to better predict our risks based on what we know about our own organization. Scenarios with specific root causes can be forecasted at our own organizations in powerful ways, similar to the expert elicitation approaches that appear in nuclear and aerospace, and continuously in meteorology.
2. A root cause must appear in data breach notifications.
Breach notification law is fragmented across the world with varying standards. Even when compulsory, many of these notifications are not publicly available. Today, the opportunity for a proper feedback loop is too often wasted.
Further, notifications are rarely describing what happened in a useful way. Notifications are generally apology letters with a number of victims attached.
Incidents and the circumstances that caused them are going into a black hole every single day.
There’s plenty of reasons why a company would not want to disclose a breach, and plenty more why they wouldn’t want to disclose how it happened. I don’t need to discuss those. What matters is somehow getting this data to be prolific, common, and accessible, and overcoming these barriers.
With the sparse data currently that is currently available, obvious trends appear. Examples: W2 data is extremely valuable to attackers. Ransomware is on the rise and innovating. Credential re-use is tried and true, and still on the rise.
These can be gleaned from typically vague phrases in the manual review of data breach notifications, but data breach notifications often don’t include any root cause language. Entire trends of breach data are lost, and our ability to perform quantitative reasoning is floored as a result.
Here’s what we‘re missing, for instance:
“Given that we’re in the tax preparation industry, our baseline probability of a W2 related breach is 18% annually.
Our forecast, given our preparations, reduces that to 9%”
This sort of statement shouldn’t feel difficult to obtain and many security people are uncomfortable with such statements.
This is a weakness of ours. Other industries are familiar with probabilistic phrases and forecasts. Those people already know that forecasts are always wrong, and a “best guess” can be really valuable, especially when those guesses have a great track record. Forecasts can only endeavor towards being more right, while still understanding the decision making value of a forecast.
Many industries are familiar with prioritizing efforts as closely to the unknown expected values associated with a risk as possible. They are not smugly convinced that they can predict the future. They are aware of the shortcomings of forecasts and probabilistic measurement. We’ll have to build and learn ours as well, especially as our prediction events involve actively evil people.
Nuclear regulation provides centrally accessible root cause data.
The NRC’s Event Notification Reports are a pretty interesting read, coming from an incident response perspective. They are extremely detailed compared to the breach data we are used to. They will cite specific model numbers involved with failures, detailed impacts, and explicit root causes. Example:

This minor, inconsequential incident around nuclear material has better root cause data than maybe any data breach notification I’ve ever seen. It’s even better than some of the lazier postmortems done by IR teams I’ve come across, even when they’re confidential.
A larger flow of root cause data would allow security teams to rationally prioritize security efforts, based on unbiased incident trends with proportionate consideration of their own company’s individualized risks.
3. Security efforts must require a probabilistic result.
Just about every concept in the profession of information security can be wielded as a probabilistic tool. Even if you believe uncertainty is extremely high (for instance, the area of APT, and whether you’re compromised), we still have extensive tooling available to measurably reduce our uncertainties about a scenario.
Meteorologists still predict the weather even in places without the preferred data available to them. In security, we must predict risk even when facing nuance, fluctuating context, and uncertainty. This uncertainty creates no excuses. Simple statistical methods are compatible with our intuitions and the measurement of our uncertainty, and are well practiced elsewhere.
Here are some examples of difficulty in weather forecasting:
A NOAA satellite is often offline, we have terrible data to forecast weather in Rwanda, and sometimes meteorologists mess up even with proper data.
Despite these uncertainties, weather professionals still do their best to forecast the weather, as their goal is always to become less wrong. We’re the same way, we already make decisions based on our intuition, but we are not excluded from quantifying our forecasts.
Excuses do not include fast paced technology, intelligent threat actors that evade measurement, and the famous we don’t know what we don’t know. We should still do our best to forecast risks and demand data that supports improved forecasts.
Everything from red teams, to attribution, to security engineering management need to become probabilistic. Malware analysis, social engineering, awareness… it’s all compatible with probabilistic methods!
All known security concepts inform our opinions about whether a “bad thing” is going to happen or not. For some reason, we’re simply afraid of forecasting “bad things” because we’re afraid of forecasting without complete data, and being accused of guessing.
The opposite is true: Having uncertainty about a future risk is exactly when forecasting is valuable, and all of our innovations in the security industry influence our uncertainty in big ways. Our industry is entirely based on a constant series of guesses, and we sadly do so without relying on the proper sciences that are unknowingly relevant when we apply our intuitions to problems.
In fact, the role of forecasting seems to become wider as data becomes more sparse. The book series on “How to Measure Anything” is the best organization of known research into forecast rigor I’ve been able to find. We may be able to expand the sciences around forecasting further than other industries, just because of the extremely volatile nature of our problem space.
In the absence of data, a forecast or estimate fills the void, and creates a demand for more data, improving a forecast, and so on. There are known ways to decrease the bias of subjective opinion, making them quantifiable, with better consistency and reduced volatility.
This aspect of forecasting in cyber security is where I am currently spending most of my time, because it makes up for shortcomings in the first two areas I’ve spoken about. Where forecasting fails, data must catch up. Where data doesn’t catch up, the forecast fills in. We can build security programs that weaponized the principles of quantitative decision making, and invest in an industry that can really begin to learn from itself.
Conclusion
I’d like to be part of an industry that can revolutionize itself.
My belief is that without accepting the role of probability into the goals of security, our industry will continue to do poorly. We need to formalize and invest in the feedback loop of data breaches. We need to create a practice of high quality validated learning for our industry, and everyone can take part in these methods.
I’m hoping that industry leaders will take time to understand and hopefully recognize a need for a value shift towards risk measurement that is usable for engineers. We need the ability to measure which innovations have the most impact.
Ryan McGeehan writes about security on Medium.
